Note
Go to the end to download the full example code.
Off-policy Q-learning#
This example tries to reproduce the results from the linear MPC numerical experiment in [5], but in an off-polic setting. We are given an RL environment whose cost function is
where \(s\) is the state, \(a\) is the action, \(w\) is a weight vector, and \(\underline{s}\) and \(\overline{s}\) are the lower and upper bounds of the state, respectively. The dynamics of the real environment are
where \(e \sim \mathcal{U}(-0.1, 0)\). Given the state \(s_k\), the following MPC scheme is used to control the system
with \(\gamma = 0.9\), and the learnable parameters are
The parameters are initialized differently, and in particular, the prediction model of the MPC is initialized wrongly as
and \(S\) is the solution to the corresponding discrete-time algebraic Riccati equation, i.e., computed with the wrong dynamics matrices. The task is simple: find a parametrization \(\theta\) such that the cost function is minimized. To solve it, we will employ a second-order LSTD Q-learning algorithm. However, we will train this agent with data generated in an off-policy fashion, i.e., generated by another controller.
import logging
from collections.abc import Callable
from typing import Any, Optional
import casadi as cs
import gymnasium as gym
import numpy as np
import numpy.typing as npt
from csnlp import Nlp
from csnlp.wrappers import Mpc
from gymnasium.spaces import Box
from gymnasium.wrappers import TimeLimit
from mpcrl import Agent, LearnableParameter, LearnableParametersDict, LstdQLearningAgent
from mpcrl.optim import NewtonMethod
from mpcrl.util.control import dlqr
from mpcrl.wrappers.agents import Evaluate, Log, RecordUpdates
Defining the environment#
First things first, we need to build the environment. We will use the gymnasium
library to do so. The most important methods are gymnasium.Env.reset and
gymnasium.Env.step, which will be called to reset the environment to its
initial state and to step the dynamics and receive a realization of the reward signal,
respectively. The environment is defined as a the following class.
class LtiSystem(gym.Env[npt.NDArray[np.floating], float]):
"""A simple discrete-time LTI system affected by uniform noise."""
nx = 2 # number of states
nu = 1 # number of inputs
A = np.asarray([[0.9, 0.35], [0, 1.1]]) # state-space matrix A
B = np.asarray([[0.0813], [0.2]]) # state-space matrix B
x_bnd = (np.asarray([[0], [-1]]), np.asarray([[1], [1]])) # bounds of state
a_bnd = (-1, 1) # bounds of control input
w = np.asarray([[1e2], [1e2]]) # penalty weight for bound violations
e_bnd = (-1e-1, 0) # uniform noise bounds
action_space = Box(*a_bnd, (nu,), np.float64)
def reset(
self,
*,
seed: Optional[int] = None,
options: Optional[dict[str, Any]] = None,
) -> tuple[npt.NDArray[np.floating], dict[str, Any]]:
"""Resets the state of the LTI system."""
super().reset(seed=seed, options=options)
self.x = np.asarray([0, 0.15]).reshape(self.nx, 1)
return self.x, {}
def get_stage_cost(self, state: npt.NDArray[np.floating], action: float) -> float:
"""Computes the stage cost :math:`L(s,a)`."""
lb, ub = self.x_bnd
return (
0.5
* (
np.square(state).sum()
+ 0.5 * action**2
+ self.w.T @ np.maximum(0, lb - state)
+ self.w.T @ np.maximum(0, state - ub)
).item()
)
def step(
self, action: cs.DM
) -> tuple[npt.NDArray[np.floating], float, bool, bool, dict[str, Any]]:
"""Steps the LTI system."""
action = float(action)
x_new = self.A @ self.x + self.B * action
x_new[0] += self.np_random.uniform(*self.e_bnd)
r = self.get_stage_cost(self.x, action)
self.x = x_new
return x_new, r, False, False, {}
Defining the MPC controller#
The second component is the MPC controller. We’ll create a custom that, of course,
inherits from csnlp.wrappers.Mpc. The implementation is as follows, and it is
in line with the theory presented above.
class LinearMpc(Mpc[cs.SX]):
"""A simple linear MPC controller."""
horizon = 10
discount_factor = 0.9
learnable_pars_init = {
"V0": np.asarray(0.0),
"x_lb": np.asarray([0, 0]),
"x_ub": np.asarray([1, 0]),
"b": np.zeros(LtiSystem.nx),
"f": np.zeros(LtiSystem.nx + LtiSystem.nu),
"A": np.asarray([[1, 0.25], [0, 1]]),
"B": np.asarray([[0.0312], [0.25]]),
}
def __init__(self) -> None:
N = self.horizon
gamma = self.discount_factor
w = LtiSystem.w
nx, nu = LtiSystem.nx, LtiSystem.nu
x_bnd, a_bnd = LtiSystem.x_bnd, LtiSystem.a_bnd
nlp = Nlp[cs.SX]()
super().__init__(nlp, N)
# parameters
V0 = self.parameter("V0")
x_lb = self.parameter("x_lb", (nx,))
x_ub = self.parameter("x_ub", (nx,))
b = self.parameter("b", (nx, 1))
f = self.parameter("f", (nx + nu, 1))
A = self.parameter("A", (nx, nx))
B = self.parameter("B", (nx, nu))
# variables (state, action, slack)
x, _ = self.state("x", nx, bound_initial=False)
u, _ = self.action("u", nu, lb=a_bnd[0], ub=a_bnd[1])
s, _, _ = self.variable("s", (nx, N), lb=0)
# dynamics
self.set_affine_dynamics(A, B, c=b)
# other constraints
self.constraint("x_lb", x_bnd[0] + x_lb - s, "<=", x[:, 1:])
self.constraint("x_ub", x[:, 1:], "<=", x_bnd[1] + x_ub + s)
# objective
A_init, B_init = self.learnable_pars_init["A"], self.learnable_pars_init["B"]
S = cs.DM(dlqr(A_init, B_init, 0.5 * np.eye(nx), 0.25 * np.eye(nu))[1])
gammapowers = cs.DM(gamma ** np.arange(N)).T
self.minimize(
V0
+ cs.bilin(S, x[:, -1])
+ cs.sum2(f.T @ cs.vertcat(x[:, :-1], u))
+ 0.5
* cs.sum2(
gammapowers * (cs.sum1(x[:, :-1] ** 2) + 0.5 * cs.sum1(u**2) + w.T @ s)
)
)
# solver
opts = {
"expand": True,
"print_time": False,
"bound_consistency": True,
"calc_lam_x": True,
"calc_lam_p": False,
"fatrop": {"max_iter": 500, "print_level": 0},
}
self.init_solver(opts, solver="fatrop", type="nlp")
Behaviour policy#
Q-learning is a versatile algorithm that can learn in an off-policy fashion, i.e., from data generated by a different policy than the one being learned. Since we wish to learn in an off-policy fashion, we need to create a behaviour policy to generate training data. To this end, we can employ a non-learning agent that uses the nominal MPC controller. However, we could use simpler policies (e.g., LQR), or even more complex, expert policies.
def get_behaviour_policy() -> Callable[[npt.NDArray[np.floating]], float]:
"""Returns a function that implements a behaviour policy."""
nominal_agent = Agent(LinearMpc(), LinearMpc.learnable_pars_init.copy())
def _policy(state: npt.NDArray[np.floating]) -> float:
action, _ = nominal_agent.state_value(state, True)
return float(action)
return _policy
Simulation#
So far, we have only defined the classes for the environment, the MPC controller, and the off-policy behaviour policy. Now, it is time to integrate these and run the simulation. This is comprised of multiple steps, which are detailed below.
We instantiate the environment. Note how it is wrapped in
gymnasium.wrappers.TimeLimitto impose a maximum amount of steps to be simulated. Note also that the Q-learning policy will NOT interact with this environment, but rather the behaviour policy will.We instantiate the MPC controller and define its learnable parameters.
We instantiate the Q-learning agent. We pass different options to it, such as the update strategy, the optimizer, the Hessian type, etc. For plotting purposes, it is also wrapped such that the updated parameters are recorded. We also log the progress of the simulation. Additionally, we evaluate the performance of the agent periodically to monitor its progress (since it is trained from offline data).
We define the behaviour policy.
We run the simulation. Under the hood, the agent will sequentially collect data from the other policy and update the parameters of the MPC controller.
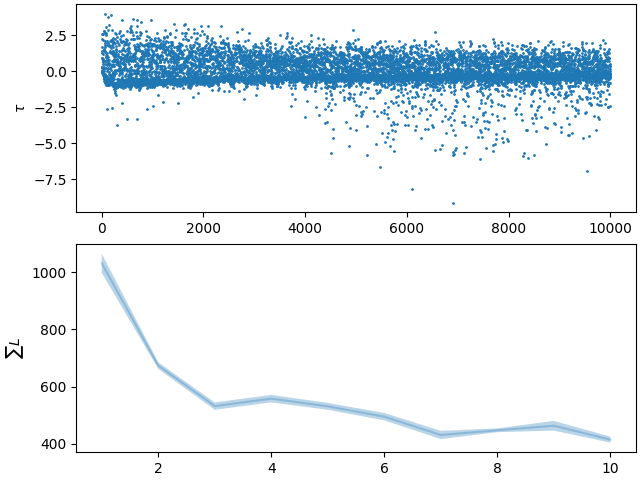
Finally, we plot the results. The first plot shows the TD error and the periodic evaluations of the learned policy. The second plot shows how each learnable parameter evolves over time.
if __name__ == "__main__":
# instantiate the env and wrap it
env = TimeLimit(LtiSystem(), 100)
# now build the MPC and the dict of learnable parameters
seed = 69
mpc = LinearMpc()
learnable_pars = LearnableParametersDict(
(
LearnableParameter(name, val.shape, val)
for name, val in mpc.learnable_pars_init.items()
)
)
# build and wrap appropriately the agent
agent = Evaluate(
Log(
RecordUpdates(
LstdQLearningAgent(
mpc=mpc,
learnable_parameters=learnable_pars,
discount_factor=mpc.discount_factor,
update_strategy=1,
optimizer=NewtonMethod(learning_rate=5e-2),
hessian_type="approx",
record_td_errors=True,
remove_bounds_on_initial_action=True,
)
),
level=logging.DEBUG,
log_frequencies={"on_episode_end": 1},
),
eval_env=TimeLimit(LtiSystem(), 100),
hook="on_episode_end",
frequency=10,
n_eval_episodes=5,
seed=seed,
)
# before training, let's create a nominal non-learning agent which will be used to
# generate expert rollout data. This data will then be used to train the off-policy
# q-learning agent.
behaviour_policy = get_behaviour_policy()
# finally, we can launch the off-policy training by just passing the
# `behaviour_policy` to the `train` method of the agent. This will use that policy
# to generate learning data, instead of the agent's own policy.
agent.train(env=env, episodes=100, behaviour_policy=behaviour_policy, seed=seed + 1)
eval_returns = np.asarray(agent.eval_returns)
# plot the results
import matplotlib.pyplot as plt
_, axs = plt.subplots(2, 1, constrained_layout=True)
eval_returns_avg = eval_returns.mean(1)
eval_returns_std = eval_returns.std(1)
evals = np.arange(1, eval_returns.shape[0] + 1)
axs[0].plot(agent.td_errors, "o", markersize=1)
axs[0].set_ylabel("Time steps")
axs[0].set_ylabel(r"$\tau$")
patch = axs[1].fill_between(
evals,
eval_returns_avg - eval_returns_std,
eval_returns_avg + eval_returns_std,
alpha=0.3,
)
axs[1].plot(evals, eval_returns_avg, color=patch.get_facecolor())
axs[1].set_ylabel("Evaluations")
axs[1].set_ylabel(r"$\sum L$")
_, axs = plt.subplots(3, 2, constrained_layout=True, sharex=True)
updates_history = {k: np.asarray(v) for k, v in agent.updates_history.items()}
axs[0, 0].plot(updates_history["b"])
axs[0, 1].plot(np.stack([updates_history[n][:, 0] for n in ("x_lb", "x_ub")], -1))
axs[1, 0].plot(updates_history["f"])
axs[1, 1].plot(updates_history["V0"])
axs[2, 0].plot(updates_history["A"].reshape(-1, 4))
axs[2, 1].plot(updates_history["B"].squeeze())
axs[0, 0].set_ylabel("$b$")
axs[0, 1].set_ylabel("$x_1$")
axs[1, 0].set_ylabel("$f$")
axs[1, 1].set_ylabel("$V_0$")
axs[2, 0].set_ylabel("$A$")
axs[2, 1].set_ylabel("$B$")
plt.show()

LstdQLearningAgent0@2026-03-11,08:54:31> training of <TimeLimit<LtiSystem instance>> started.
LstdQLearningAgent0@2026-03-11,08:54:32> episode 0 ended with rewards=93.341.
LstdQLearningAgent0@2026-03-11,08:54:33> episode 1 ended with rewards=83.554.
LstdQLearningAgent0@2026-03-11,08:54:34> episode 2 ended with rewards=121.326.
LstdQLearningAgent0@2026-03-11,08:54:35> episode 3 ended with rewards=84.026.
LstdQLearningAgent0@2026-03-11,08:54:36> episode 4 ended with rewards=96.134.
LstdQLearningAgent0@2026-03-11,08:54:37> episode 5 ended with rewards=87.062.
LstdQLearningAgent0@2026-03-11,08:54:38> episode 6 ended with rewards=102.175.
LstdQLearningAgent0@2026-03-11,08:54:39> episode 7 ended with rewards=101.995.
LstdQLearningAgent0@2026-03-11,08:54:40> episode 8 ended with rewards=83.826.
LstdQLearningAgent0@2026-03-11,08:54:41> episode 9 ended with rewards=98.223.
LstdQLearningAgent0@2026-03-11,08:54:41> validation of <TimeLimit<LtiSystem instance>> started.
LstdQLearningAgent0@2026-03-11,08:54:42> episode 0 ended with rewards=1037.518.
LstdQLearningAgent0@2026-03-11,08:54:42> episode 1 ended with rewards=1001.116.
LstdQLearningAgent0@2026-03-11,08:54:42> episode 2 ended with rewards=984.950.
LstdQLearningAgent0@2026-03-11,08:54:43> episode 3 ended with rewards=1065.291.
LstdQLearningAgent0@2026-03-11,08:54:43> episode 4 ended with rewards=1068.048.
LstdQLearningAgent0@2026-03-11,08:54:43> validation of <TimeLimit<LtiSystem instance>> concluded with returns=[1037.518 1001.116 984.95 1065.291 1068.048].
LstdQLearningAgent0@2026-03-11,08:54:44> episode 10 ended with rewards=82.680.
LstdQLearningAgent0@2026-03-11,08:54:45> episode 11 ended with rewards=84.286.
LstdQLearningAgent0@2026-03-11,08:54:46> episode 12 ended with rewards=93.230.
LstdQLearningAgent0@2026-03-11,08:54:47> episode 13 ended with rewards=87.473.
LstdQLearningAgent0@2026-03-11,08:54:48> episode 14 ended with rewards=90.288.
LstdQLearningAgent0@2026-03-11,08:54:49> episode 15 ended with rewards=90.401.
LstdQLearningAgent0@2026-03-11,08:54:50> episode 16 ended with rewards=85.078.
LstdQLearningAgent0@2026-03-11,08:54:51> episode 17 ended with rewards=87.989.
LstdQLearningAgent0@2026-03-11,08:54:52> episode 18 ended with rewards=85.786.
LstdQLearningAgent0@2026-03-11,08:54:53> episode 19 ended with rewards=88.925.
LstdQLearningAgent0@2026-03-11,08:54:53> validation of <TimeLimit<LtiSystem instance>> started.
LstdQLearningAgent0@2026-03-11,08:54:54> episode 0 ended with rewards=684.846.
LstdQLearningAgent0@2026-03-11,08:54:54> episode 1 ended with rewards=662.606.
LstdQLearningAgent0@2026-03-11,08:54:54> episode 2 ended with rewards=656.818.
LstdQLearningAgent0@2026-03-11,08:54:55> episode 3 ended with rewards=684.293.
LstdQLearningAgent0@2026-03-11,08:54:55> episode 4 ended with rewards=679.971.
LstdQLearningAgent0@2026-03-11,08:54:55> validation of <TimeLimit<LtiSystem instance>> concluded with returns=[684.846 662.606 656.818 684.293 679.971].
LstdQLearningAgent0@2026-03-11,08:54:56> episode 20 ended with rewards=87.625.
LstdQLearningAgent0@2026-03-11,08:54:57> episode 21 ended with rewards=99.347.
LstdQLearningAgent0@2026-03-11,08:54:58> episode 22 ended with rewards=80.428.
LstdQLearningAgent0@2026-03-11,08:54:59> episode 23 ended with rewards=79.775.
LstdQLearningAgent0@2026-03-11,08:55:00> episode 24 ended with rewards=85.188.
LstdQLearningAgent0@2026-03-11,08:55:01> episode 25 ended with rewards=96.698.
LstdQLearningAgent0@2026-03-11,08:55:02> episode 26 ended with rewards=77.502.
LstdQLearningAgent0@2026-03-11,08:55:03> episode 27 ended with rewards=96.183.
LstdQLearningAgent0@2026-03-11,08:55:04> episode 28 ended with rewards=105.890.
LstdQLearningAgent0@2026-03-11,08:55:06> episode 29 ended with rewards=82.035.
LstdQLearningAgent0@2026-03-11,08:55:06> validation of <TimeLimit<LtiSystem instance>> started.
LstdQLearningAgent0@2026-03-11,08:55:06> episode 0 ended with rewards=519.173.
LstdQLearningAgent0@2026-03-11,08:55:06> episode 1 ended with rewards=537.317.
LstdQLearningAgent0@2026-03-11,08:55:06> episode 2 ended with rewards=514.463.
LstdQLearningAgent0@2026-03-11,08:55:07> episode 3 ended with rewards=547.010.
LstdQLearningAgent0@2026-03-11,08:55:07> episode 4 ended with rewards=542.092.
LstdQLearningAgent0@2026-03-11,08:55:07> validation of <TimeLimit<LtiSystem instance>> concluded with returns=[519.173 537.317 514.463 547.01 542.092].
LstdQLearningAgent0@2026-03-11,08:55:08> episode 30 ended with rewards=82.507.
LstdQLearningAgent0@2026-03-11,08:55:09> episode 31 ended with rewards=98.136.
LstdQLearningAgent0@2026-03-11,08:55:10> episode 32 ended with rewards=88.070.
LstdQLearningAgent0@2026-03-11,08:55:11> episode 33 ended with rewards=90.383.
LstdQLearningAgent0@2026-03-11,08:55:12> episode 34 ended with rewards=98.036.
LstdQLearningAgent0@2026-03-11,08:55:13> episode 35 ended with rewards=85.680.
LstdQLearningAgent0@2026-03-11,08:55:14> episode 36 ended with rewards=81.058.
LstdQLearningAgent0@2026-03-11,08:55:15> episode 37 ended with rewards=81.554.
LstdQLearningAgent0@2026-03-11,08:55:16> episode 38 ended with rewards=75.075.
LstdQLearningAgent0@2026-03-11,08:55:17> episode 39 ended with rewards=94.047.
LstdQLearningAgent0@2026-03-11,08:55:17> validation of <TimeLimit<LtiSystem instance>> started.
LstdQLearningAgent0@2026-03-11,08:55:18> episode 0 ended with rewards=560.445.
LstdQLearningAgent0@2026-03-11,08:55:18> episode 1 ended with rewards=579.152.
LstdQLearningAgent0@2026-03-11,08:55:18> episode 2 ended with rewards=562.760.
LstdQLearningAgent0@2026-03-11,08:55:19> episode 3 ended with rewards=546.248.
LstdQLearningAgent0@2026-03-11,08:55:19> episode 4 ended with rewards=542.080.
LstdQLearningAgent0@2026-03-11,08:55:19> validation of <TimeLimit<LtiSystem instance>> concluded with returns=[560.445 579.152 562.76 546.248 542.08 ].
LstdQLearningAgent0@2026-03-11,08:55:20> episode 40 ended with rewards=91.800.
LstdQLearningAgent0@2026-03-11,08:55:21> episode 41 ended with rewards=83.729.
LstdQLearningAgent0@2026-03-11,08:55:22> episode 42 ended with rewards=82.323.
LstdQLearningAgent0@2026-03-11,08:55:23> episode 43 ended with rewards=92.013.
LstdQLearningAgent0@2026-03-11,08:55:24> episode 44 ended with rewards=108.806.
LstdQLearningAgent0@2026-03-11,08:55:25> episode 45 ended with rewards=105.735.
LstdQLearningAgent0@2026-03-11,08:55:26> episode 46 ended with rewards=77.498.
LstdQLearningAgent0@2026-03-11,08:55:27> episode 47 ended with rewards=81.884.
LstdQLearningAgent0@2026-03-11,08:55:28> episode 48 ended with rewards=122.919.
LstdQLearningAgent0@2026-03-11,08:55:30> episode 49 ended with rewards=102.503.
LstdQLearningAgent0@2026-03-11,08:55:30> validation of <TimeLimit<LtiSystem instance>> started.
LstdQLearningAgent0@2026-03-11,08:55:30> episode 0 ended with rewards=530.704.
LstdQLearningAgent0@2026-03-11,08:55:30> episode 1 ended with rewards=536.013.
LstdQLearningAgent0@2026-03-11,08:55:31> episode 2 ended with rewards=547.771.
LstdQLearningAgent0@2026-03-11,08:55:31> episode 3 ended with rewards=510.380.
LstdQLearningAgent0@2026-03-11,08:55:31> episode 4 ended with rewards=531.076.
LstdQLearningAgent0@2026-03-11,08:55:31> validation of <TimeLimit<LtiSystem instance>> concluded with returns=[530.704 536.013 547.771 510.38 531.076].
LstdQLearningAgent0@2026-03-11,08:55:32> episode 50 ended with rewards=98.532.
LstdQLearningAgent0@2026-03-11,08:55:33> episode 51 ended with rewards=87.448.
LstdQLearningAgent0@2026-03-11,08:55:34> episode 52 ended with rewards=76.950.
LstdQLearningAgent0@2026-03-11,08:55:35> episode 53 ended with rewards=90.454.
LstdQLearningAgent0@2026-03-11,08:55:36> episode 54 ended with rewards=95.364.
LstdQLearningAgent0@2026-03-11,08:55:38> episode 55 ended with rewards=88.191.
LstdQLearningAgent0@2026-03-11,08:55:39> episode 56 ended with rewards=95.595.
LstdQLearningAgent0@2026-03-11,08:55:40> episode 57 ended with rewards=115.797.
LstdQLearningAgent0@2026-03-11,08:55:41> episode 58 ended with rewards=90.789.
LstdQLearningAgent0@2026-03-11,08:55:42> episode 59 ended with rewards=96.821.
LstdQLearningAgent0@2026-03-11,08:55:42> validation of <TimeLimit<LtiSystem instance>> started.
LstdQLearningAgent0@2026-03-11,08:55:42> episode 0 ended with rewards=515.259.
LstdQLearningAgent0@2026-03-11,08:55:42> episode 1 ended with rewards=504.021.
LstdQLearningAgent0@2026-03-11,08:55:43> episode 2 ended with rewards=481.614.
LstdQLearningAgent0@2026-03-11,08:55:43> episode 3 ended with rewards=481.659.
LstdQLearningAgent0@2026-03-11,08:55:43> episode 4 ended with rewards=492.961.
LstdQLearningAgent0@2026-03-11,08:55:43> validation of <TimeLimit<LtiSystem instance>> concluded with returns=[515.259 504.021 481.614 481.659 492.961].
LstdQLearningAgent0@2026-03-11,08:55:44> episode 60 ended with rewards=96.298.
LstdQLearningAgent0@2026-03-11,08:55:46> episode 61 ended with rewards=93.016.
LstdQLearningAgent0@2026-03-11,08:55:47> episode 62 ended with rewards=95.958.
LstdQLearningAgent0@2026-03-11,08:55:48> episode 63 ended with rewards=86.612.
LstdQLearningAgent0@2026-03-11,08:55:49> episode 64 ended with rewards=90.669.
LstdQLearningAgent0@2026-03-11,08:55:50> episode 65 ended with rewards=94.776.
LstdQLearningAgent0@2026-03-11,08:55:51> episode 66 ended with rewards=91.156.
LstdQLearningAgent0@2026-03-11,08:55:52> episode 67 ended with rewards=90.788.
LstdQLearningAgent0@2026-03-11,08:55:53> episode 68 ended with rewards=88.200.
LstdQLearningAgent0@2026-03-11,08:55:54> episode 69 ended with rewards=91.326.
LstdQLearningAgent0@2026-03-11,08:55:54> validation of <TimeLimit<LtiSystem instance>> started.
LstdQLearningAgent0@2026-03-11,08:55:54> episode 0 ended with rewards=403.957.
LstdQLearningAgent0@2026-03-11,08:55:55> episode 1 ended with rewards=429.821.
LstdQLearningAgent0@2026-03-11,08:55:55> episode 2 ended with rewards=445.243.
LstdQLearningAgent0@2026-03-11,08:55:55> episode 3 ended with rewards=437.985.
LstdQLearningAgent0@2026-03-11,08:55:56> episode 4 ended with rewards=438.716.
LstdQLearningAgent0@2026-03-11,08:55:56> validation of <TimeLimit<LtiSystem instance>> concluded with returns=[403.957 429.821 445.243 437.985 438.716].
LstdQLearningAgent0@2026-03-11,08:55:57> episode 70 ended with rewards=80.850.
LstdQLearningAgent0@2026-03-11,08:55:58> episode 71 ended with rewards=106.516.
LstdQLearningAgent0@2026-03-11,08:55:59> episode 72 ended with rewards=83.796.
LstdQLearningAgent0@2026-03-11,08:56:00> episode 73 ended with rewards=78.457.
LstdQLearningAgent0@2026-03-11,08:56:01> episode 74 ended with rewards=109.057.
LstdQLearningAgent0@2026-03-11,08:56:02> episode 75 ended with rewards=113.268.
LstdQLearningAgent0@2026-03-11,08:56:03> episode 76 ended with rewards=88.253.
LstdQLearningAgent0@2026-03-11,08:56:04> episode 77 ended with rewards=97.895.
LstdQLearningAgent0@2026-03-11,08:56:05> episode 78 ended with rewards=109.405.
LstdQLearningAgent0@2026-03-11,08:56:06> episode 79 ended with rewards=91.497.
LstdQLearningAgent0@2026-03-11,08:56:06> validation of <TimeLimit<LtiSystem instance>> started.
LstdQLearningAgent0@2026-03-11,08:56:07> episode 0 ended with rewards=449.602.
LstdQLearningAgent0@2026-03-11,08:56:07> episode 1 ended with rewards=442.883.
LstdQLearningAgent0@2026-03-11,08:56:07> episode 2 ended with rewards=457.288.
LstdQLearningAgent0@2026-03-11,08:56:08> episode 3 ended with rewards=438.047.
LstdQLearningAgent0@2026-03-11,08:56:08> episode 4 ended with rewards=450.137.
LstdQLearningAgent0@2026-03-11,08:56:08> validation of <TimeLimit<LtiSystem instance>> concluded with returns=[449.602 442.883 457.288 438.047 450.137].
LstdQLearningAgent0@2026-03-11,08:56:09> episode 80 ended with rewards=76.399.
LstdQLearningAgent0@2026-03-11,08:56:10> episode 81 ended with rewards=91.720.
LstdQLearningAgent0@2026-03-11,08:56:11> episode 82 ended with rewards=87.830.
LstdQLearningAgent0@2026-03-11,08:56:12> episode 83 ended with rewards=98.009.
LstdQLearningAgent0@2026-03-11,08:56:13> episode 84 ended with rewards=106.508.
LstdQLearningAgent0@2026-03-11,08:56:15> episode 85 ended with rewards=91.359.
LstdQLearningAgent0@2026-03-11,08:56:16> episode 86 ended with rewards=76.346.
LstdQLearningAgent0@2026-03-11,08:56:17> episode 87 ended with rewards=103.364.
LstdQLearningAgent0@2026-03-11,08:56:18> episode 88 ended with rewards=96.070.
LstdQLearningAgent0@2026-03-11,08:56:19> episode 89 ended with rewards=97.707.
LstdQLearningAgent0@2026-03-11,08:56:19> validation of <TimeLimit<LtiSystem instance>> started.
LstdQLearningAgent0@2026-03-11,08:56:19> episode 0 ended with rewards=478.560.
LstdQLearningAgent0@2026-03-11,08:56:19> episode 1 ended with rewards=457.190.
LstdQLearningAgent0@2026-03-11,08:56:20> episode 2 ended with rewards=484.889.
LstdQLearningAgent0@2026-03-11,08:56:20> episode 3 ended with rewards=436.916.
LstdQLearningAgent0@2026-03-11,08:56:20> episode 4 ended with rewards=459.566.
LstdQLearningAgent0@2026-03-11,08:56:20> validation of <TimeLimit<LtiSystem instance>> concluded with returns=[478.56 457.19 484.889 436.916 459.566].
LstdQLearningAgent0@2026-03-11,08:56:21> episode 90 ended with rewards=90.802.
LstdQLearningAgent0@2026-03-11,08:56:23> episode 91 ended with rewards=100.399.
LstdQLearningAgent0@2026-03-11,08:56:24> episode 92 ended with rewards=79.348.
LstdQLearningAgent0@2026-03-11,08:56:25> episode 93 ended with rewards=88.587.
LstdQLearningAgent0@2026-03-11,08:56:26> episode 94 ended with rewards=83.780.
LstdQLearningAgent0@2026-03-11,08:56:27> episode 95 ended with rewards=98.602.
LstdQLearningAgent0@2026-03-11,08:56:28> episode 96 ended with rewards=91.807.
LstdQLearningAgent0@2026-03-11,08:56:29> episode 97 ended with rewards=94.908.
LstdQLearningAgent0@2026-03-11,08:56:30> episode 98 ended with rewards=77.406.
LstdQLearningAgent0@2026-03-11,08:56:31> episode 99 ended with rewards=82.452.
LstdQLearningAgent0@2026-03-11,08:56:31> validation of <TimeLimit<LtiSystem instance>> started.
LstdQLearningAgent0@2026-03-11,08:56:31> episode 0 ended with rewards=419.862.
LstdQLearningAgent0@2026-03-11,08:56:32> episode 1 ended with rewards=428.491.
LstdQLearningAgent0@2026-03-11,08:56:32> episode 2 ended with rewards=408.493.
LstdQLearningAgent0@2026-03-11,08:56:32> episode 3 ended with rewards=398.053.
LstdQLearningAgent0@2026-03-11,08:56:33> episode 4 ended with rewards=419.368.
LstdQLearningAgent0@2026-03-11,08:56:33> validation of <TimeLimit<LtiSystem instance>> concluded with returns=[419.862 428.491 408.493 398.053 419.368].
LstdQLearningAgent0@2026-03-11,08:56:33> training of <TimeLimit<LtiSystem instance>> concluded with returns=[ 93.341 83.554 121.326 84.026 96.134 87.062 102.175 101.995 83.826
98.223 82.68 84.286 93.23 87.473 90.288 90.401 85.078 87.989
85.786 88.925 87.625 99.347 80.428 79.775 85.188 96.698 77.502
96.183 105.89 82.035 82.507 98.136 88.07 90.383 98.036 85.68
81.058 81.554 75.075 94.047 91.8 83.729 82.323 92.013 108.806
105.735 77.498 81.884 122.919 102.503 98.532 87.448 76.95 90.454
95.364 88.191 95.595 115.797 90.789 96.821 96.298 93.016 95.958
86.612 90.669 94.776 91.156 90.788 88.2 91.326 80.85 106.516
83.796 78.457 109.057 113.268 88.253 97.895 109.405 91.497 76.399
91.72 87.83 98.009 106.508 91.359 76.346 103.364 96.07 97.707
90.802 100.399 79.348 88.587 83.78 98.602 91.807 94.908 77.406
82.452].
Total running time of the script: (2 minutes 4.865 seconds)
Estimated memory usage: 223 MB