Module reference#
This page contains all the detailed information about the modules and classes in
mpcrl. First, we will indulge in presenting the core components of the library
that allow us to easily implement Reinforcement Learning algorithms. Then, we will move
to the agents themselves, which contain these algorithms and deploy them to control the
given environments (and possibly learn from interacting with it). Finally, the different
optimization strategies that can be used to update the parameters of the MPC controller
are reported, and the utility functions and wrappers that can be used to enhance the
behaviour of the agents are also presented.
Core components#
Before jumping into the details of the agents and their Reinforcement Learning algorithms, we present here the core elements that are used during training and evaluation, but are not the agents themselves.
The mpcrl.core submodule implements various core functionalities of the MPC-RL
framework. These allow to define various hyperparameters to, e.g., specify the frequency
of the RL updates, use experience replay, introduce exploration in the MPC policy. At
the same time, it contains foundations for specifying the learnable parameters, and
implement the hook-callback mechanism that allows to customize the training loop to a
high degree.
We’ll start first with the latter, i.e., the building blocks of the library, and only then move to the other former, i.e., the other core elements that allow to specify the hyperparameters for our agents.
Building blocks#
In this section, we present the building blocks of the package, which are at the core of the internal workings of the agents and their learning algorithms. These include the callback mechanisms, the learnable parameters, the scheduling quantities, and our custom exceptions and warnings.
Callbacks#
As it will be clear from the inheritance diagram in Agents, all agents are derived from mixin classes that define callbacks and manage hooks attached to these callbacks. This system allows not only the user to customize the behaviour of a derived agent every time a callback is triggered, but also to easily implement and manage all those events and quantities that need to be scheduled during training and evaluation. Some examples of such events are the decay of the learning rate or the exploration chances, or when and with which frequency to invoke an update of the MPC parametrization. Here we list the classes that enable this system, but for an introduction to the callbacks and how to use them, see Callbacks.
A class with the particular purpose of creating, storing and deleting hooks attached to callbacks. |
|
Class with callbacks for agents. |
|
Class with callbacks for learning agents. |
Learnable parameters#
Given an MPC controller with several symbolic parameters (some meant to be learned, some other not), we need a way to specify to the agent of choice which of these are indeed learnable. This is done by the use of the two classes introduced in this submodule.
Namely, LearnableParameter allows to embed a single parameter and its
information, while LearnableParametersDict is a dictionary-like class that
contains several of these LearnableParameter instances, and offers different
properties and methods to manage them in bulk.
See also Learnable parameters.
A parameter that is learnable, that is, it can be adjusted via RL or any other learning strategy. |
|
|
Scheduling quantities#
What if you need to decay or increase your learning rate over time during training? The following submodule provides a set of schedulers that can be used to update or decay different quantities, such as learning rates or exploration probability, over time. Most of the agents will then accept a scheduler as an argument, which will be updated according to the user-specified way.
A submodule providing both base classes for schedulers and some concrete implementations for the most common cases, such as linearly and exponentially decaying schedulers. |
Exceptions#
Finally, we also provide two custom warnings and exceptions to signal two distinct and
important events, namely, when the MPC solver fails to find a solution, and when the
update fails (usually the QP solver fails to find a solution). Since the methods
mpcrl.Agent.evaluate, mpcrl.LearningAgent.train and
mpcrl.LearningAgent.train_offpolicy accept the raises argument, we provide
here both warnings and exceptions that can be raised in case of failures, depending on
the value of said flag. We also provide two utility functions to conveniently raise
these exceptions or warnings.
Error and warning classes for signaling failure in the MPC solver and in the updates, as well as convenience functions for raising these errors and warnings. |
Hyperparameters#
Update strategy#
The update strategy is likely to be one of the most important aspects that a designer
has to consider when training a Reinforcement Learning agent. When instantiating an
agent, via UpdateStrategy, the user can specify when and with which frequency
to update the agent’s MPC parametrization (e.g., at the end of every training episode,
or every N time steps), as well as the number of updates to skip at the beginning
(in case we need to wait for experience buffers to properly fill first). See
Updating for a more thorough explanation.
A class holding information on the update strategy to be used by the learning algorithm. |
Experience replay#
Naively, Reinforcement Learning algorithms can dish out an update of the MPC
parametrization at every time step, by leveraging only the current information. However,
as in Deep RL, it makes sense to enable the agent to store past experiences and
re-use them, or at least use them in a batched fashion, to improve the stability and
convergence learning process. ExperienceReplay allows a learning agent to store
and sample, when performing an update, past experiences. See
Experience for a more detailed explanation.
Class for Reinforcement Learning agents' traning to save and sample experience transitions. |
Exploring#
Exploration is a fundamental concept in Reinforcement Learning. Without it, often the learning algorithms converge to very suboptimal solutions, or don’t even work.
This submodule contains base classes and implementations for exploration strategies in the context of MPC-based RL. These classes allow the agent to draw perturbations to apply then to the MPC’s optimal action, thus inducing exploration. Mathematically speaking, this can be achieved in two distinct ways, or modes:
additive: this is the simplest way to apply perturbations. When the MPC solver provides the optimal action to take in the environment’s current state \(s\) by solving the state value function problem \(\min_{u} V(s)\), before applying the action to the environment, the agent will draw a perturbation \(p\) from the exploration stratey and apply the action \(\tilde{u} = u + p\) to the environment.
gradient-based: this is a more sophisticated way to apply perturbations. We can induce exploration more safely by modifying the objective of the state value function as \(\min_{u} V(s) + p^\top u_0\), where \(p\) is the random perturbation and \(u_0\) is the first action in the NLP problem. This way, we can perturb the gradient of the solution based on the scale of the first action.
See Exploration for a more thorough explanation. In any case, whichever mode is selected, all the modifications and perturbations are taken care of automatically by the agent and the exploration strategy.
Base abstract class for exploration strategies. |
|
Strategy where no exploration is allowed at any time or, in other words, the policy is always deterministic (only based on the current state, and not perturbed). |
|
Fully greedy strategy that always perturbs randomly the MPC policy. |
|
Epsilon-greedy strategy for perturbing the policy, which only occasionally perturbs randomly the MPC policy. |
|
Exploration based on the Ornstein-Uhlenbeck Brownian motion with friction. |
|
Wrapper-like exploration that keeps the wrapped base exploration strategy constants for a number of steps, thus creating a piecewise exploration. |
Warmstarting the MPC solvers#
More often than not, the agent is given a nonlinear MPC problem to solve at each time step. It is well-known that NLP problems are proned to convergence to local minima, and a simple yet effective way to counter this is to solve the same problem multiple times with different initial conditions. This is known as a warmstart strategy.
WarmStartStrategy allows the user to specify a warmstart strategy for the NLP
solver of the MPC. In particular, the user can select which past solution to use as the
initial guess for the next iteration, and whether to generate structured or random
guesses around that solution to further explore the solution space and possibly converge
to a better solution. Moreover, the user can choose how this strategy should keep up
with new solutions.
This class makes heavy use of csnlp.multistart, so be sure to check the
documentation of that module for more basic information. See also
Warmstarting.
Class containing all the information to guide the warmstart strategy for the MPC's NLP in order to speed up computations (by selecting appropriate initial conditions) and to support multiple initial conditions. |
Agents#
Agents are the main and, arguably, the most important components of the package. They deploy the control policies to control the given environments, and, if they are learning-based, also implement the underlying learning algorithm to tune the parameters of the control policies.
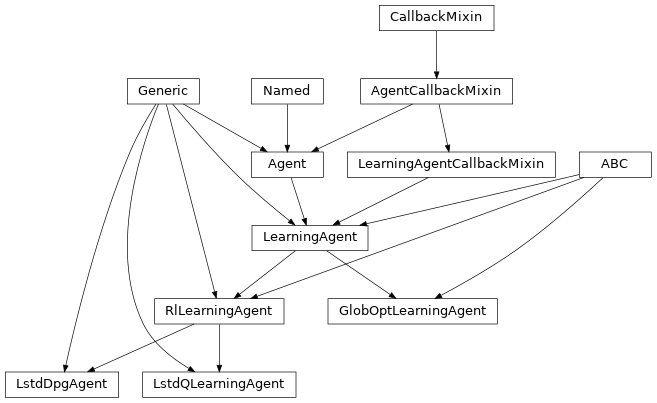
Base agents#
What follows are the base classes for the agents in the package. These are either
non-learning agents (i.e., Agent) or abstract learning agents that provide the
layout for inheriting classes.
Simple MPC-based agent with a fixed (i.e., non-learnable) MPC controller. |
|
Base abstract class for a learning agent with MPC as policy provider. |
|
Base abstract class for learning agents that employe gradient-based RL strategies to learn/improve the MPC policy. |
Reinforcement Learning agents#
These are the learning agents that leverage a reinforcement learning algorithm to tune the parametrization of the MPC controller. Two very common algorithms are here implemented: Q-learning and Deterministic Policy Gradient (DPG).
Other learning agents#
We also provide other learning agents that do not use gradient-based approaches to
update their parameters, but rather rely on other global gradient-free optimization
techniques. See also optim.GradientFreeOptimizer.
Class for learning agents that employ gradient-free Global Optimization strategies (e.g., Bayesian Optimization) to learn/improve the MPC policy. |
Optimizers#
This submodule contains the optimizers that are used to update the parameters of the
agent’s MPC scheme. These are mainly gradient-based, i.e., they exploit Jacobian (and
possibly Hessian) information to update the parameters. However, as we will see below,
the submodule also allows for gradient-free optimization techniques (to be combined with
mpcrl.GlobOptLearningAgent). See also Optimizers.
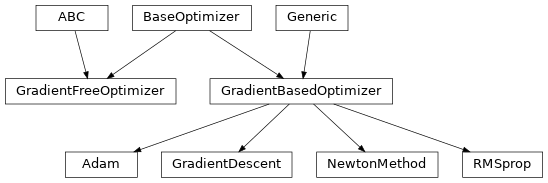
Base optimizers#
These are the base abstract optimizer classes that lay the skeleton for the gradient-based updates of the MPC parametrization. We also offer an interface for gradient-free optimizers, which can be used to tune the parameters of the MPC controller via global optimization strategies such as Bayesian Optimization.
Base class for optimization algorithms. |
|
Base class for first- and second-order gradient-based optimization algorithms. |
|
Base class for gradient-free optimization algorithms, e.g., Bayesian Optimization. |
Gradient-based optimizers#
Here instead are reported the concrete implementations of the gradient-based optimizers that can be used to update the parameters of the MPC controller. They include both first-order and second-order methods, whether they require and make use of gradient and curvature information (i.e., Jacobian and Hessian of some quantity w.r.t. to the parameters).
First-order Gradient descent optimizer, based on [14] and |
|
Second-order gradient-based Newton's method. |
|
First-order gradient-based Adam and AdamW optimizers, based on [9] and |
|
RMSprop optimizer, based on [8] and |
Other submodules#
mpcrl offers a few other components that are not explicitly needed by the agents
and their core functionalities, but can be useful to enhance the base behaviour of
agents via wrappers, or to provide additional methods for, e.g., designing LQR
controllers. To this end, we provide a few utility wrapper classes and utility methods
in the following submodules.